1. 概要
2025年8月24日(日)に開催予定の第6回 岐阜AI勉強会の準備のため、GPT2, BERT 等の処理内容を分析して表示する ecco を Goole Colab で動かしました。
インストールに必要なスクリプト、ecco を使用したスクリプト、ecco が出力したインタラクティブな JavaScript をこちらのリンクに Google Colab のページとしてアップロードしました。
2. 背景
AI の Transformer モデルをイラスト付きで説明したページ The Illustrated Transformer がわかり易く、イラストも見易かったため、第3回から第5回の岐阜AI勉強会で上記のリンク先のサイトの記事を順に追っていくことにしました。
第六回の岐阜AI勉強会では下記のページを追っていく予定です。その中の 1. と 2. で使用されている Python モジュール ecco が 2022年1月の v0.1.2 からバージョンアップされておらず、1. と 2. のページからリンクが張られている Google Colab のページのコードセルを実行しても ecco をインストールして動作させることはできませんでした。
そのため、私のほうで 2025年7月31日に試した ecco をインストールし、実行する Google Colab のページをこちらにアップロードしました。
- Interfaces for Explaining Transformer Language Models
- Finding the Words to Say: Hidden State Visualizations for Language Models
- The Illustrated Retrieval Transformer
3. ecco と transformers のインストール
Google Colab のコードセルに下記のように入力して実行しても ecco をインストールすることはできませんでした。
!pip install ecco
ですが、コードセルに下記のように入力して実行すると、ecco をインストールすることができました。ecco 0.1.2 がインストールされました。
!pip install git+https://github.com/jalammar/ecco.git
最新の transformers のモジュールでは ecco 0.1.2 を使用した Python スクリプトを実行することができなかったため、下記のコマンドをコードセルに入力して実行し、transfomers 4.24.0 をインストールしました。
!pip install transformers==4.24.0
4. ecco を使用した Input Saliency のスクリプトの実行
4.1. 下記のスクリプトをコードセルに入力して実行します。
import ecco
lm = ecco.from_pretrained('gpt2')
prompt="Heathrow airport is located in the city of"
output = lm.generate(prompt, generate=1, do_sample=False, attribution=['ig'])
output.primary_attributions(attr_method='ig')
![]()
GPT2 (この投稿では GPT-2 small, GPT-2 (117M) を GPT2 と表記します) が予測した Token がどの入力 Token の影響をより強く受けていたかが色で表示されます。濃い色の Token がより強い影響を与えています。バックプロパゲーションで計算される各入力 Token の勾配と、各入力 Token のベクトルの積を要素ごとに取り、その二乗和を影響度の強さ (Input Saliency) としています。
ある入力 Token ベクトルの勾配が他の入力 Token ベクトルの勾配より大きいということは、その Token ベクトルをわずかに変えただけで出力の選択に大きな影響を与えることになり、出力への影響が大きいことになります。
4.2. 下記の Python スクリプトをコードセルに入力して実行します。上記 4.1. の Python スクリプトとの違いは最後の行のメソッド引数に style=”detailed” が追加されている点です。
import ecco
lm = ecco.from_pretrained('gpt2')
prompt="Heathrow airport is located in the city of"
output = lm.generate(prompt, generate=1, do_sample=False, attribution=['ig'])
output.primary_attributions(attr_method='ig', style="detailed")

上記 4.1. の Python スクリプトの出力とは異なり、各入力 Token が出力 Token の選択に与えた影響を数値で表しています。上記 4.1. と同様にして計算された各入力 Token の Input Saliency の大きさの比を割合で表しています。
4.3. 下記の Python スクリプトをコードセルに入力して実行します。
import ecco
lm = ecco.from_pretrained('gpt2')
prompt="In summer, when I hear the sound of cicadas,"
output = lm.generate(prompt, generate=10, do_sample=True, attribution=['ig'])
output.primary_attributions(attr_method='ig', style="detailed")
下から二行目のメソッドのパラメータに generate=10 を追加し、10 の Token を予測して出力するようにしています。
![]()
このページには画像を貼り付けましたが、実際に出力されるのはマウスカーソルで選択した出力 Token に対する Input Saliency の数値を表示する JavaScript になります。上の画像の例ではマウスで feels を選択しています。
5. ecco を使用した Neuron Activations の分析
FFNN のニューロンの活動 (Neuron Activations) を NMF (Non-negative Matrix Factorization) で分析する ecco のメソッドを試しました。
GPT2 をモデルとして使用した場合は出力が文字化けしてしまったため、下記のコードセルでは DistilBERT と BERT を使用しました。
入力として使用した英文は私のこちらの Blog ページから抜粋した文章になります。
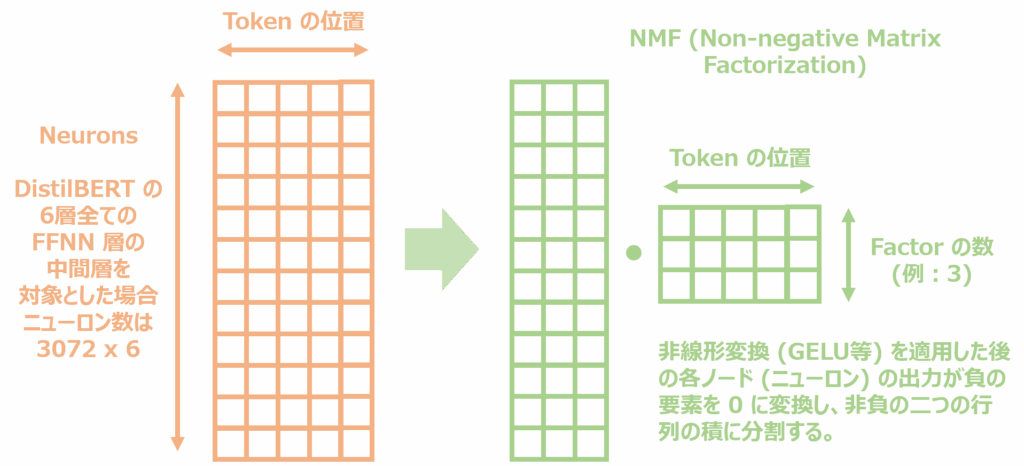
ecco の 分析では、下の画像のように FFNN のニューロンの活動を NMF で非負の二つの行列に分割します。メソッド引数として指定した Factor の数に FFNN のニューロンの活動を分割します。出力されるグラフは Factor を行、各 Token を列とする行列の値に対応するグラフです。FFNN のニューロンの活動を複数のグループに分割したグラフとなっています。
5.1. DistilBERT の全ての層の FFNN 層を対象とした場合
import ecco
lm = ecco.from_pretrained('distilbert-base-uncased', activations=True)
text = 'Other species I saw on foot were Japanese grass lizards moving along the edges of the road, horseflies or carpenter bees flying near flowers with low buzzing sounds, small birds that I don’t see very often, and crows. I also heard a low buzzing sound coming from the high voltage lines. I thought the horseflies and carpenter bees, which fly with a low buzzing sound for their size, might alert humans and other animals with their sound.'
inputs = lm.tokenizer([text], return_tensors="pt")
output = lm(inputs)
nmf_1 = output.run_nmf(n_components=8)
nmf_1.explore()

low, high, small のような形容詞、a, the のような冠詞、カンマとピリオド、末尾の [SEP]、lizards, bees, animals, humans のような名詞、i とそれに続く単語、sound, see, heard, buzzing のような知覚動詞や音に関する Factor 等に分離されました。
5.2. DistilBERT の最初の層の FFNN 層を対象とした場合
import ecco
lm = ecco.from_pretrained('distilbert-base-uncased', activations=True)
text = 'Other species I saw on foot were Japanese grass lizards moving along the edges of the road, horseflies or carpenter bees flying near flowers with low buzzing sounds, small birds that I don’t see very often, and crows. I also heard a low buzzing sound coming from the high voltage lines. I thought the horseflies and carpenter bees, which fly with a low buzzing sound for their size, might alert humans and other animals with their sound.'
inputs = lm.tokenizer([text], return_tensors="pt")
output = lm(inputs)
nmf_1 = output.run_nmf(n_components=8, from_layer=0, to_layer=1)
nmf_1.explore()

上記 5.1. の結果と比較するとオレンジ色の Factor 3 のように前半部分の Token により強く反応する Factor が見られます。
5.3. DistilBERT の最後の層の FFNN 層を対象とした場合
import ecco
lm = ecco.from_pretrained('distilbert-base-uncased', activations=True)
text = 'Other species I saw on foot were Japanese grass lizards moving along the edges of the road, horseflies or carpenter bees flying near flowers with low buzzing sounds, small birds that I don’t see very often, and crows. I also heard a low buzzing sound coming from the high voltage lines. I thought the horseflies and carpenter bees, which fly with a low buzzing sound for their size, might alert humans and other animals with their sound.'
inputs = lm.tokenizer([text], return_tensors="pt")
output = lm(inputs)
nmf_1 = output.run_nmf(n_components=8, from_layer=5, to_layer=6)
nmf_1.explore()

末尾の [SEP] のみに強く応答する Factor はなく、5.1. と 5.2. の結果と比較すると Token ポジションに強く応答する Factor が消えています。
5.4. BERT の全ての層の FFNN 層を対象とした場合
import ecco
lm = ecco.from_pretrained('bert-base-uncased', activations=True)
text = '''Other species I saw on foot were Japanese grass lizards moving along the edges of the road, horseflies or carpenter bees flying near flowers with low buzzing sounds, small birds that I don’t see very often, and crows. I also heard a low buzzing sound coming from the high voltage lines. I thought the horseflies and carpenter bees, which fly with a low buzzing sound for their size, might alert humans and other animals with their sound.'''
inputs = lm.tokenizer([text], return_tensors="pt")
output = lm(inputs)
nmf_1 = output.run_nmf(n_components=8)
nmf_1.explore()

上記 5.1. の DistilBERT の全ての層の FFNN 層を対象とした場合と同じではありませんが、[SEP] のみに対応した Factor、カンマとピリオドに対応する Factor、i のみに対応する Factor、i に続く単語をまとめた Factor 等があり、似た点もあります。
5.5. BERT の最後の層の FFNN 層を対象とした場合
import ecco
lm = ecco.from_pretrained('bert-base-uncased', activations=True)
text = '''Other species I saw on foot were Japanese grass lizards moving along the edges of the road, horseflies or carpenter bees flying near flowers with low buzzing sounds, small birds that I don’t see very often, and crows. I also heard a low buzzing sound coming from the high voltage lines. I thought the horseflies and carpenter bees, which fly with a low buzzing sound for their size, might alert humans and other animals with their sound.'''
inputs = lm.tokenizer([text], return_tensors="pt")
output = lm(inputs)
nmf_1 = output.run_nmf(n_components=8, from_layer=11, to_layer=12)
nmf_1.explore()

上記 5.3. と同様、末尾の [SEP] のみに強く応答する Factor はありません。カンマとピリオドに対応する Factor、i とそれに続く単語等に応答する Factor が見られました。
6. ecco を使用した各層の出力 (Hidden States) の分析
6.1. 下記のスクリプトは GPT2 の最終層から出力された次の Token を生成する Hidden States のベクトルを調べ、最もスコアが高かった Token から順に 10 の Token の候補を出力します。
import ecco
lm = ecco.from_pretrained('gpt2', verbose=False)
prompt=""" Heathrow airport is located in the city of"""
output = lm.generate(prompt, generate=1, do_sample=False)
output.layer_predictions(position=9, layer=11)

London 以外のイギリスの都市が二番目以降の候補として並んでいます。
6.2. 下記のスクリプトは GPT2 の 12 の各層から出力された Hidden States のベクトルを調べ、最もスコアが高かった Token から順に 10 の Token の候補を出力します。上記 6.1. と同様、プロンプトで指定した入力 Token に続く、position=9 の Token を対象としています。
import ecco
lm = ecco.from_pretrained('gpt2', verbose=False)
prompt=""" Heathrow airport is located in the city of"""
output = lm.generate(prompt, generate=1, do_sample=False)
output.layer_predictions(position=9)

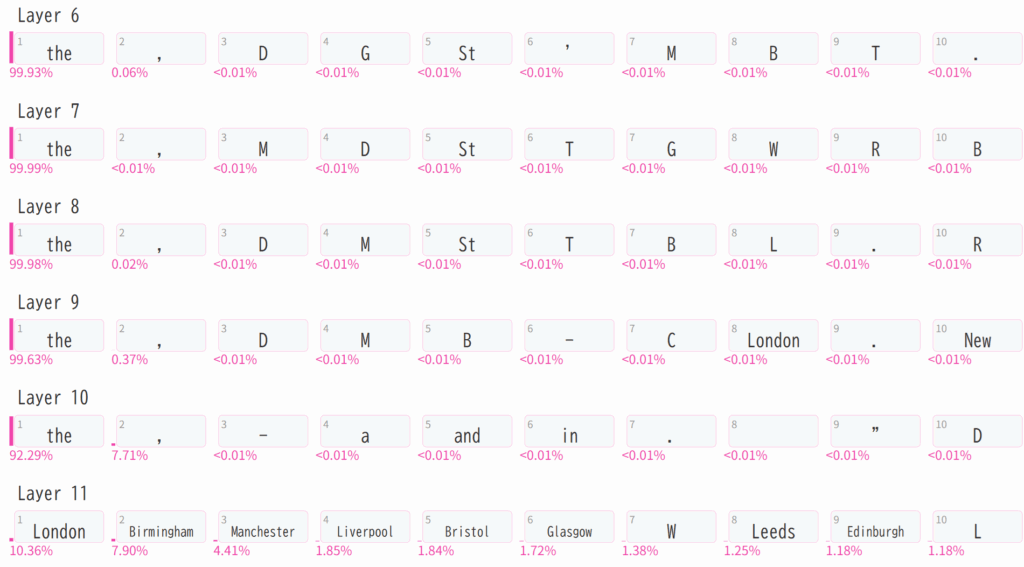
Layer 9 の出力 Hidden States の 8 番目の候補として London が一度出力されていますが、それを除くと最終層の Layer 11 になるまでイギリスの都市は候補として提示されていません。
下記のスクリプトは先ほどとは異なる入力 The capital of Japan is the city of を与えています。
import ecco
lm = ecco.from_pretrained('gpt2', verbose=False)
prompt=""" The capital of Japan is the city of"""
output = lm.generate(prompt, generate=1, do_sample=False)
output.layer_predictions(position=8)
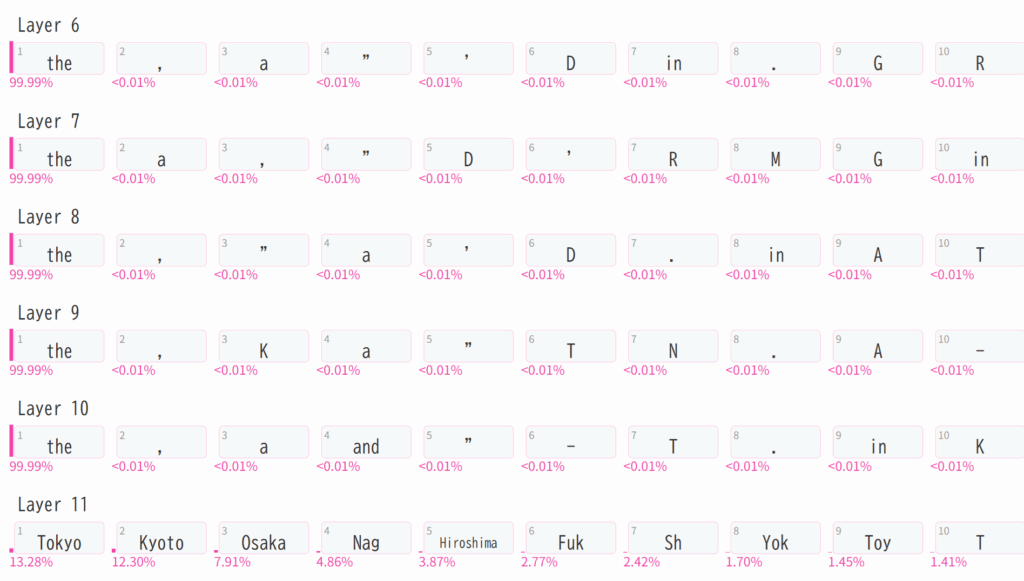
こちらは Layer 6 以降の出力のみを画像として添付しました。最終層の Layer 11 になるまで日本の都市は候補として提示されていません。
Finding the Words to Say: Hidden State Visualizations for Language Models に記載された解説ページの例のように 1, 1, 1, に続く Token を推測する場合と異なり、都市名のような固有名詞は最終層になるまでトップ 10 には入りにくいようです。
6.3. 下記のスクリプトは Heathrow airport is located in the city of の次に来る Token が GPT2 の各レイヤーを経た後、何番目の候補となっていたかを表す図を出力します。
import ecco
lm = ecco.from_pretrained('gpt2')
prompt="Heathrow airport is located in the city of"
output = lm.generate(prompt, generate=1, do_sample=False)
output.rankings()
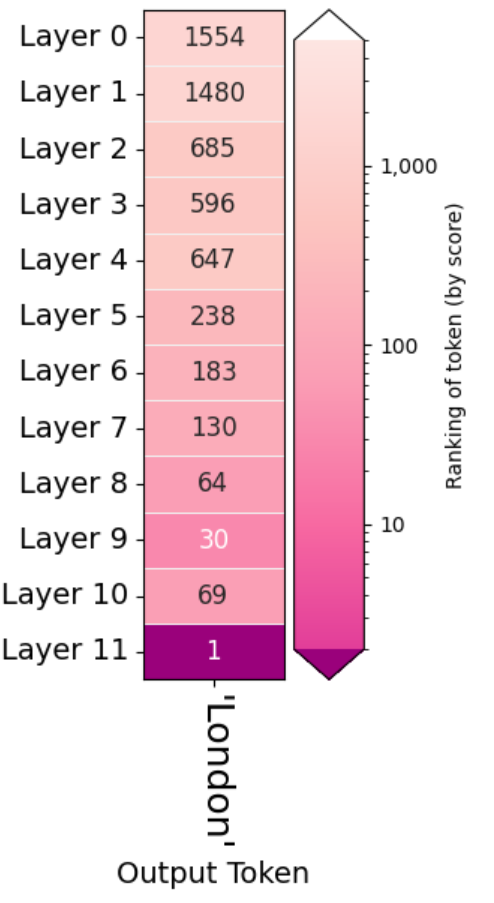
London の順位が層を経るごとに上昇してきています。ただし、Layer 9 から Layer 10 に移るときに下がっています。また、上記 6.2. の例と異なり Layer 9 の出力における London の順位は 8 ではなく 30 になっています。
プロンプトの入力文字列を上記 6.2. の例に合わせ、下記のように書き換えたところ Layer 9 の出力の順位は 8 になりました。
import ecco
lm = ecco.from_pretrained('gpt2')
prompt=""" Heathrow airport is located in the city of"""
output = lm.generate(prompt, generate=1, do_sample=False)
output.rankings()
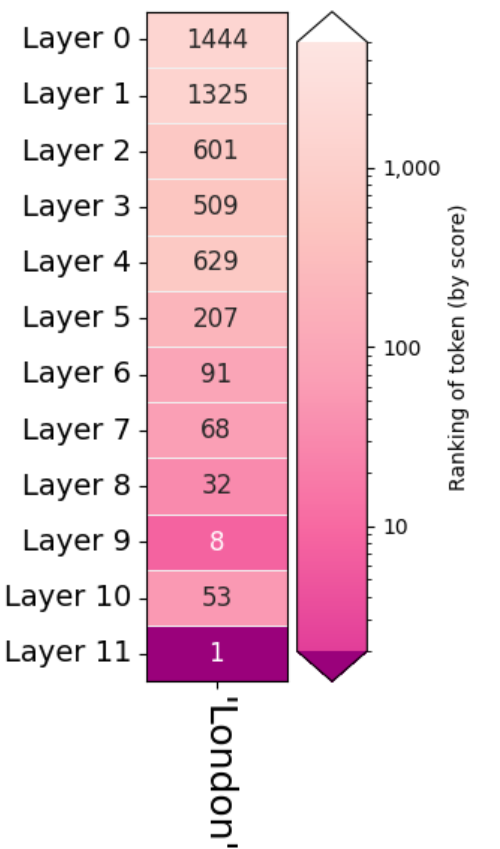
prompt=”Heathrow airport is located in the city of” のときは Heathrow が He ath row のような Token に分割され、prompt=””” Heathrow airport is located in the city of””” のときは Heath row のような Token に分割されるのを確認しています。
どちらの場合も、Layer 9 から Layer 10 に移るときに London の順位は下がっています。
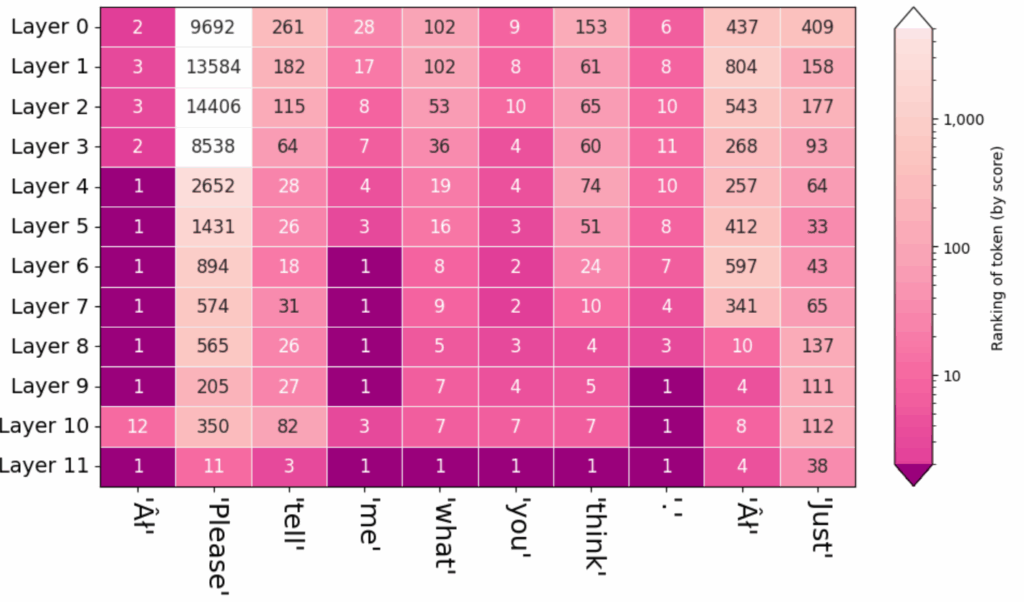
6.4. 下記のスクリプトは Good afternoon. に続く 10 の Token が GPT2 の各レイヤーを経た後、何番目の候補となっていたかを表す図を出力します。
import ecco
lm = ecco.from_pretrained('gpt2')
prompt="Good afternoon. "
output = lm.generate(prompt, generate=10, do_sample=False)
output.rankings()
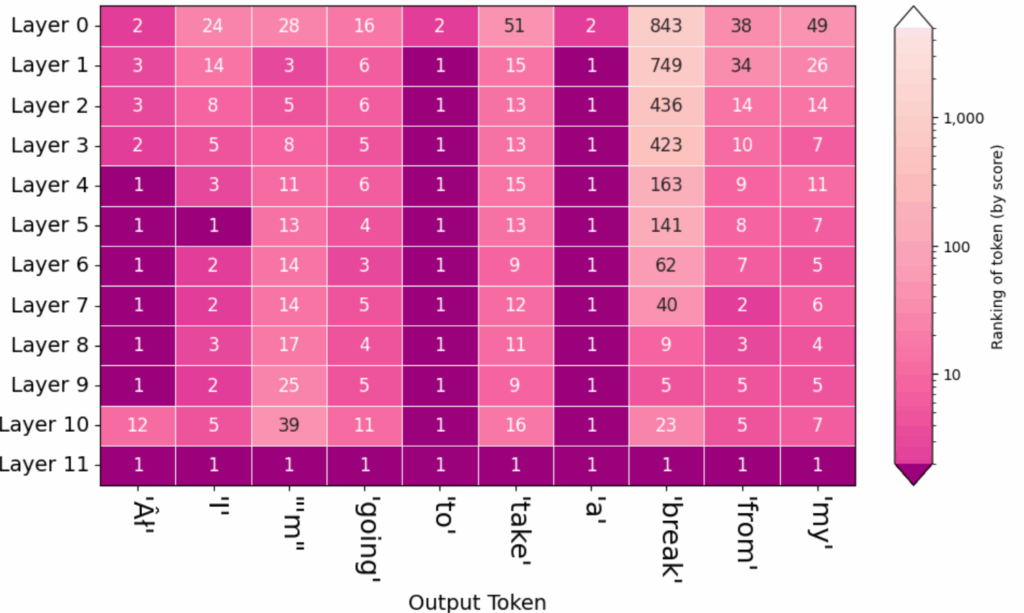
この例では、上記 6.2. と 6.3. の例の地名を出力する場合と異なり、よく使われる一般的な単語が出力されています。to と a のような単語は Layer 1 の出力からランキング 1 が続いています。
その他:
最初に AI という Token が出力されています。ハット付きの A とストロークを付けた I となっています。
Google Colab のコードセルにテキストとして出力された文章は I’m going to take a break from my となっており、ランキングの図のみに出力されていました。
6.5. 下記のスクリプトは 6.4. と同様、Good afternoon. に続く 10 の Token が GPT2 の各レイヤーを経た後、何番目の候補となっていたかを表す図を出力します。こちらは 6.4. と異なり generate メソッドの引数を do_sample=True としています。最もスコアが高い候補以外もサンプルするようにしています。
import ecco
lm = ecco.from_pretrained('gpt2')
prompt="Good afternoon. "
output = lm.generate(prompt, generate=10, do_sample=True)
output.rankings()